
OCR CuneiForm, также известная как CuneiForm OpenOCR и Cognitive OpenOCR, — программа для распознавания печатного текста на сканах, фотографиях страниц и графических файлах. Она относится к классическим OCR-системам: пользователь подаёт на вход изображение документа, программа анализирует страницу, выделяет текстовые области, распознаёт символы и сохраняет результат в редактируемом виде.
CuneiForm важна не только как отдельная программа для распознавания текста, но и как исторический пример OCR-системы, которая прошла путь от коммерческого продукта до открытой технологии. Изначально CuneiForm была Windows-программой Cognitive Technologies, позже код был открыт, а отдельная ветка была перенесена на Linux Юсси Пакканеном. Linux-порт проверялся на Linux, FreeBSD, OS X и Windows-сборках через MSVC, MinGW и Cygwin; среди известных ограничений этой ветки — работа на x86 и amd64, а также отсутствие распознавания таблиц в Linux-порте.
В практическом смысле OCR CuneiForm подходит для перевода скана в редактируемый текст, распознавания русского и английского текста, обработки печатных документов, извлечения текста из изображений и автоматизации распознавания через командную строку. Для пользователей, которым нужен графический интерфейс, вокруг CuneiForm появились оболочки, в том числе Cuneiform-Qt и OCRFeeder. Cuneiform-Qt открывает сканированное изображение, показывает его в области предварительного просмотра, распознаёт текст через CuneiForm и сохраняет результат в HTML.
Если задача связана с электронными документами, PDF-читалками, конвертацией и смежными офисными утилитами, логично смотреть и соседние материалы сайта: раздел электронных документов, читалок, текстовых редакторов, а также программы вроде WinScan2PDF, PDFsam, PDF-XChange Viewer, Adobe Acrobat Reader и Foxit Reader.
Что такое OCR CuneiForm OpenOCR
OCR CuneiForm — система оптического распознавания символов для печатного текста. Она не сводится к простому извлечению букв: в CuneiForm есть анализ разметки страницы и распознавание текстового формата. Командная версия принимает входное изображение, обрабатывает его и сохраняет результат в одном из поддерживаемых форматов. В CuneiForm доступны форматы html, hocr, native, rtf, smarttext, text; обычный текст используется по умолчанию.
Название CuneiForm встречается в нескольких вариантах, и это важно учитывать при чтении старых обзоров, инструкций и обсуждений:
| Название | Что обычно подразумевается |
|---|---|
| OCR CuneiForm | исходная OCR-программа Cognitive Technologies |
| CuneiForm OpenOCR | открытая версия системы распознавания |
| Cognitive OpenOCR | Windows-ориентированное название продукта на некоторых каталогах ПО |
| CuneiForm for Linux | порт CuneiForm для Linux и других систем |
| Cuneiform-Qt | графическая Qt-оболочка для CuneiForm |
| OCRFeeder с CuneiForm | сценарий, когда CuneiForm используется как OCR-движок внутри другой графической OCR-среды |
Главное отличие OCR CuneiForm от современных облачных OCR-сервисов — локальная модель работы. Командная версия запускается на компьютере, принимает файл изображения и создаёт файл результата. Такой подход удобен для автоматизации: команду можно встроить в скрипт, обработчик сканов или цепочку предварительной подготовки документов.
CuneiForm распознаёт несколько языков. В командной версии язык выбирается параметром -l; без явного выбора распознаётся английский текст. Среди поддерживаемых языковых кодов есть eng, rus, ruseng, ger, fra, spa, ita, ukr, bul, cze, dan, dut, est, pol, por, swe, tur и другие. Для русско-английских документов предусмотрен отдельный код ruseng, что важно для инструкций, счетов, накладных и технических текстов со смешанными обозначениями.
Краткая карточка OCR CuneiForm
| Параметр | Описание |
|---|---|
| Полное название | OCR CuneiForm / CuneiForm OpenOCR / Cognitive OpenOCR |
| Разработчик исходной системы | Cognitive Technologies |
| Тип программы | OCR-система для распознавания печатного текста |
| Основная задача | перевод сканов и изображений с текстом в редактируемый документ |
| Распознавание | печатные документы, сканы, изображения страниц |
| Языки | английский по умолчанию; русский, смешанный русский/английский и ряд европейских языков через параметр -l |
| Форматы результата | text, smarttext, rtf, html, hocr, native |
| Графические оболочки | Cuneiform-Qt, OCRFeeder и другие фронтенды |
| Командная работа | cuneiform [параметры] input |
| Специальные режимы | --dotmatrix, --fax, --singlecolumn |
| Особенность Linux-порта | проверялся на Linux, FreeBSD, OS X и Windows-сборках; в этой ветке нет распознавания таблиц |
| Ограничение по архитектуре Linux-порта | x86 и amd64 |
| Близкие альтернативы | Tesseract OCR, ABBYY FineReader PDF, OCRFeeder, GOCR, Ocrad |
OCR CuneiForm хорошо раскрывается в двух сценариях. Первый — графическая работа с отдельной страницей, когда пользователь видит изображение, запускает распознавание и сохраняет результат. Второй — командная обработка, когда CuneiForm используется как OCR-движок внутри автоматизированной цепочки.
История программы и развитие версий
Коммерческий период CuneiForm
CuneiForm появилась как OCR-система Cognitive Technologies. В 2007 году CNews писал, что компания была образована в 1993 году, а OCR CuneiForm распознаёт полиграфические и машинописные гарнитуры разных начертаний, а также шрифты, получаемые с принтеров, за исключением декоративных и рукописных. Это важная граница применимости: программа рассчитана на печатный текст, а не на рукописные заметки, каллиграфию или декоративные надписи.
Профильная пресса связывала CuneiForm с массовым распространением OCR через комплектацию сканеров и МФУ. В архиве Мир ПК за 2008 год CuneiForm описана как одна из распространённых технологий распознавания текста, которой комплектовались модели сканеров Hewlett-Packard, Canon, Mustek, Kodak, Fujitsu, Primetex, Olivetti и других производителей.
Этот период объясняет интерфейсную логику программы: OCR CuneiForm ориентирована не только на готовые изображения, но и на работу со сканером, выбор драйвера, настройку области сканирования, яркости, контраста, порога и режима страницы. На старых скриншотах Windows-версии видны элементы, связанные с TWAIN-сканером, настройками распознавания, языком, поиском картинок и цветами блоков.
Переход к бесплатной и открытой модели
12 декабря 2007 года OCR CuneiForm стала бесплатной программой для распознавания печатного текста. В тот же период был обозначен курс на открытие кода. В апреле 2008 года код Cuneiform был открыт, для распространения выбрали BSD-лицензию, а исходные тексты стали доступны со 2 апреля 2008 года.
Этот переход изменил роль CuneiForm. Программа перестала быть только готовым Windows-приложением для конечного пользователя и стала базой для портов, оболочек и экспериментов в открытом ПО. Для технических пользователей особенно важной стала командная ветка Cuneiform for Linux: она позволила запускать распознавание из терминала, использовать CuneiForm в скриптах и подключать движок к графическим фронтендам.
Linux-порт и Cuneiform for Linux
Cuneiform for Linux — отдельная ветка, в которой исходная Windows-программа была перенесена на Linux. CuneiForm изначально была Windows-программой, портированной на Linux Юсси Пакканеном. Версия проверялась на Linux, FreeBSD, OS X и Windows через MSVC, MinGW и Cygwin.
Linux-порт важен не только для пользователей Linux. Он показывает, как OCR CuneiForm отделилась от классического Windows-интерфейса и стала OCR-движком, который можно вызывать из других программ. Такая модель удобна для пакетной обработки: сканер или другой инструмент создаёт изображение, CuneiForm распознаёт текст, следующий этап сохраняет результат, индексирует его или отправляет в редактор.
Ограничения Linux-порта нужно учитывать заранее. В этой ветке нет распознавания таблиц, а работа ограничена x86 и amd64. Для задач, где важно восстановить таблицы из бухгалтерских документов, прайс-листов, отчётов или анкет, это существенный минус. Для обычного текста, инструкций, писем, страниц книг и одно- или многоколонных материалов CuneiForm остаётся применимой при хорошем качестве исходника.
Хронология развития открытой ветки
В CNews собрана лента событий вокруг Cognitive CuneiForm: декабрь 2007 года — бесплатная версия, апрель 2008 года — открытие кода системы распознавания, август 2008 года — Linux-версия ядра, октябрь 2008 года — открытие исходных текстов интерфейса, июль 2010 года — новая версия системы распознавания текстов Cuneiform для Linux.
Отдельная публикация на Хабре за июль 2010 года фиксирует выход версии 1.0 Cuneiform Linux: в ней удалён код сомнительного лицензионного происхождения и исправлено множество ошибок. Код Cuneiform Linux распространялся под упрощённой BSD-лицензией и был основан на коде CuneiForm, открытом Cognitive Technologies в 2008 году.
| Этап | Что изменилось для пользователя |
|---|---|
| Коммерческая Windows-программа | пользователь работал с готовым графическим приложением для сканирования и распознавания |
| Бесплатная версия | OCR CuneiForm стала доступнее для массового применения |
| Открытие кода | появилась основа для портирования, оболочек и интеграции |
| Linux-порт | CuneiForm стал удобнее для терминала, скриптов и Linux-сред |
| Cuneiform-Qt | появился простой графический фронтенд с открытием изображения, распознаванием и сохранением результата |
| Использование в OCRFeeder | CuneiForm стал одним из движков внутри графической OCR-среды |
Интерфейс OCR CuneiForm
Главное окно Windows-версии
Windows-интерфейс OCR CuneiForm выглядит как классическая настольная программа для сканирования и распознавания. В верхней части размещены меню File, Edit, View, Recognition, Window, Help, ниже — панель инструментов. В рабочей области отображается страница, блоки разметки и увеличенная строка текста в нижней части окна. Такой интерфейс рассчитан на ручную проверку: пользователь видит исходник, может оценить структуру страницы и перейти к распознаванию.
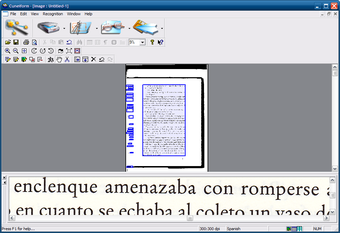
На скриншоте видно, что OCR CuneiForm работает не только как автоматический распознаватель без контроля пользователя. Пользователь видит страницу, область предварительного просмотра и элементы разметки. Это полезно при распознавании печатных документов со сложной структурой: журналов, инструкций, фрагментов книг, технических листов, документов с иллюстрациями.
Нижняя увеличенная область помогает оценить качество исходного изображения. Если текст размытый, буквы сливаются, строка повернута или скан имеет слабый контраст, ошибки распознавания появляются уже на этапе анализа строки. Для таких случаев важна подготовка изображения: правильная ориентация, достаточная чёткость, отсутствие сильного шума, нормальный контраст.
Настройки сканирования
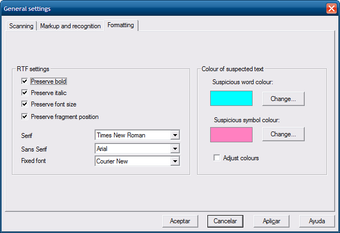
В окне General settings есть вкладка Scanning: здесь видны поля и элементы для выбора драйвера, размера изображения, границ, разрешения, режима цвета, яркости, контраста и порога. Такие параметры важны, когда OCR CuneiForm используется не с готовым файлом, а вместе со сканером.
Эти параметры напрямую связаны с результатом OCR. Слишком низкое разрешение ухудшает форму букв; чрезмерный контраст разрушает тонкие элементы шрифта; слабый порог оставляет серый фон и шум. Для печатного текста CuneiForm лучше работает с исходником, где буквы отделены от фона, строки не наклонены, а поля не заполнены посторонними отметками.
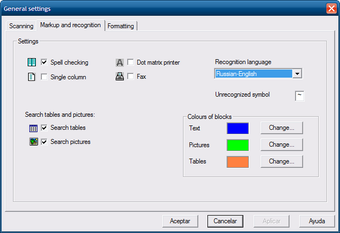
Настройки разметки и распознавания
Во вкладке Markup and recognition видны параметры Spell checking, Single column, Dot matrix printer, Fax, выбор Recognition language, а также настройки цветов блоков для текста, картинок и таблиц. Эти элементы хорошо показывают архитектуру программы: CuneiForm не только распознаёт символы, но и работает с разметкой страницы, режимом документа и словарной проверкой.
Single column нужен для страниц с одной колонкой. Этот режим отключает анализ сложной структуры и обрабатывает изображение как одноколоночный текст. В командной версии тот же смысл имеет параметр --singlecolumn: он отключает анализ разметки страницы и считает, что изображение состоит из одной текстовой колонки.
Dot matrix printer и Fax соответствуют специальным режимам для матричной печати и факсов. В командной строке они представлены параметрами --dotmatrix и --fax: первый оптимизирует распознавание текста, напечатанного на матричном принтере, второй — текста, прошедшего через факс.
Recognition Wizard
Окно Recognition Wizard: Image показывает выбор источника изображения: Open... для файла и вариант со сканером. В интерфейсе также есть кнопка Change... для изменения выбранного источника. Такой мастер подходит для пользователя, который распознаёт отдельный документ пошагово: сначала выбирает источник, затем настраивает параметры и запускает обработку.
Такой формат особенно понятен при разовой обработке: открыть изображение, выбрать язык, запустить распознавание, проверить результат. Для регулярной работы с десятками страниц удобнее командная версия или графическая среда, в которой есть управление несколькими документами.
Cuneiform-Qt как простая оболочка
Cuneiform-Qt — графический фронтенд для CuneiForm. Его окно устроено проще: сверху меню File, Settings, Help, ниже кнопки Open image, Recognize text, Save result. Основная область поделена на две части: Source Image для исходной картинки и Recognized text для результата. Cuneiform-Qt написан на Qt для Linux, а его задача — открыть сканированное изображение, показать его, распознать текст через CuneiForm и сохранить результат в HTML.

Cuneiform-Qt хорошо подходит для объяснения базового процесса OCR CuneiForm. Пользователь открывает изображение, нажимает Recognize text, получает текст в правой области и сохраняет результат. В отличие от полноценной Windows-оболочки, здесь нет перегруженного набора настроек; программа работает как простой мост между изображением и движком распознавания.
Основные возможности OCR CuneiForm
Распознавание печатного текста
OCR CuneiForm предназначена для печатных документов. Она работает с полиграфическими и машинописными шрифтами, но не предназначена для рукописного текста и декоративных шрифтов. Это ограничение важно учитывать до запуска: если исходник состоит из рукописных заметок, подписей, нестандартных логотипов или сильно стилизованных букв, CuneiForm не является подходящим инструментом.
На практике программа полезна для таких материалов:
сканы книг и брошюр;
страницы инструкций;
машинописные документы;
распечатанные письма;
архивные документы с печатным текстом;
факсовые копии;
сканы с русским и английским текстом;
изображения страниц, которые нужно перенести в редактируемый текст.
Для качественного распознавания исходник должен быть читаемым. OCR-движок работает с формой символов: если у буквы разрушены контуры, строка наклонена, фон неравномерный, а текст размыт, ошибки появляются не из-за формата результата, а из-за качества изображения.
Анализ разметки страницы
CuneiForm выполняет layout analysis — анализ разметки страницы. Это означает, что программа определяет не только отдельные символы, но и структуру документа: текстовые области, расположение строк и формат. CuneiForm работает как OCR-система с анализом разметки страницы и распознаванием текстового формата.
Анализ разметки полезен, когда документ состоит не из одного сплошного абзаца, а из нескольких областей. Примеры:
двухколонный текст;
страница с заголовком и основным блоком;
документ с подписью под изображением;
лист с несколькими текстовыми зонами;
инструкция, где текст разбит на короткие фрагменты.
При одноколоночном документе сложный анализ страницы не нужен. В таком случае режим --singlecolumn помогает программе не искать сложную структуру и воспринимать страницу как одну колонку текста.
Выбор языка распознавания
Язык распознавания задаётся параметром -l. Это один из самых важных параметров OCR CuneiForm: движок сравнивает распознанные формы символов с языковой моделью и словарными ожиданиями. Неправильный язык приводит к типичным ошибкам: русские буквы путаются с латиницей, английские сокращения искажены, смешанный документ теряет часть слов.
Примеры языков:
| Код | Язык |
|---|---|
eng | English |
rus | Russian |
ruseng | mixed Russian/English |
ger | German |
fra | French |
spa | Spanish |
ita | Italian |
ukr | Ukrainian |
pol | Polish |
swe | Swedish |
tur | Turkish |
В обычных русских документах используется rus. Для инструкций, накладных, технических описаний и документов с англоязычными маркировками лучше использовать ruseng. Такой вариант уменьшает риск, что английские обозначения, артикулы, марки устройств, единицы измерения и латинские сокращения будут распознаны как русские слова.
Специальные режимы для сложных исходников
В CuneiForm есть режимы, которые отражают реальные проблемы старых документов:
| Параметр | Задача |
|---|---|
--dotmatrix | распознавание текста, напечатанного матричным принтером |
--fax | распознавание текста, прошедшего через факс |
--singlecolumn | обработка страницы как одной текстовой колонки |
-f | выбор формата результата |
-l | выбор языка распознавания |
-o | выбор файла результата |
--dotmatrix нужен для документов с точечной структурой символов. Такие страницы встречаются в старых бухгалтерских распечатках, транспортных документах, квитанциях и ведомостях. Обычный OCR может воспринимать точки как шум или неправильно собирать контуры букв; специальный режим меняет подход к распознаванию такого текста.
--fax ориентирован на факсовые копии. Факс часто даёт полосы, искажения, неровные края букв и снижение контрастности. Отсканированная факсовая страница выглядит хуже обычной печати, поэтому специальный режим помогает работать именно с таким типом исходника.
--singlecolumn важен для простых страниц. Если документ — это один столбец текста, отключение анализа сложной разметки снижает риск неверного порядка блоков.
Форматы результата
CuneiForm сохраняет результат в нескольких форматах. Выбор зависит от того, что пользователь планирует делать после распознавания.
| Формат | Для чего подходит |
|---|---|
text | простой текст без сложной структуры |
smarttext | plain text с TeX-параграфами |
rtf | редактируемый документ с форматированием |
html | результат в HTML |
hocr | HTML-разметка hOCR для OCR-пайплайнов |
native | внутренний формат Cuneiform 2000 |
text удобен для копирования, поиска, индексации и последующей обработки скриптами. rtf полезен, когда результат нужно открыть в текстовом редакторе и сохранить часть оформления. html подходит для просмотра в браузере и дальнейшей публикации. hocr нужен там, где важна разметка OCR-результата и координаты текстовых блоков в машинно обрабатываемой форме.
Как пользоваться OCR CuneiForm
Подготовка изображения
Качество OCR начинается до запуска программы. CuneiForm распознаёт символы на изображении, поэтому исходник должен быть подготовлен как документ, а не как фотография для чтения глазами. Человек легко угадывает слово по контексту, а OCR-движок чувствителен к форме букв, контрасту, наклону и шуму.
Перед распознаванием проверьте:
страница ориентирована правильно, текст не повернут на 90 или 180 градусов;
строки идут горизонтально, без сильного перекоса;
текст не размыт;
фон достаточно светлый, буквы достаточно тёмные;
на странице нет теней от сгиба книги;
поля не перекрывают текст;
язык выбран правильно;
для факса или матричной печати выбран подходящий режим;
для одноколоночной страницы не включён лишний анализ сложной структуры.
Для старых документов особенно важны контраст и правильный цветовой режим. ITC в обзоре OCR CuneiForm V.12 указывал, что качество распознавания повышается при увеличении контрастности документа и переводе в чёрно-белый режим; там же отмечалось приемлемое качество при разрешении от 200 до 400 пикселов на дюйм.
Распознавание через графический интерфейс OCR CuneiForm
В Windows-интерфейсе базовый процесс строится вокруг изображения страницы и команды распознавания. Пользователь работает не с абстрактным файлом, а с видимой страницей: выбирает исходник, проверяет область скана, настраивает распознавание, запускает обработку и смотрит текст.
Типовая последовательность:
Открыть изображение или выбрать сканер через мастер
Recognition Wizard.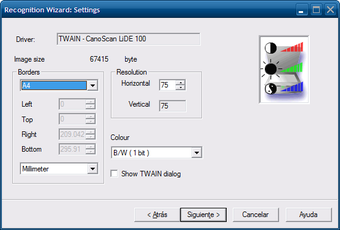
Проверить, что страница отображается правильно и не повёрнута.
В настройках разметки выбрать язык в поле
Recognition language.Для простого одноколоночного документа включить
Single column.Для матричной распечатки включить
Dot matrix printer.Для факсовой копии включить
Fax.Запустить распознавание через меню
Recognitionили соответствующую кнопку панели.Проверить результат и исправить ошибки.
Сохранить результат в подходящем формате.
Такой процесс особенно подходит для единичных страниц, где важен ручной контроль. Пользователь видит, как программа воспринимает страницу, и может изменить настройки до сохранения результата.
Распознавание через Cuneiform-Qt
Cuneiform-Qt делает процесс максимально коротким. В окне есть три основные кнопки: Open image, Recognize text, Save result. Слева отображается исходник в области Source Image, справа — распознанный текст в Recognized text.
Порядок работы:
Нажмите
Open image.Выберите изображение с текстом.
Проверьте, что страница видна в области
Source Image.Нажмите
Recognize text.Посмотрите результат в области
Recognized text.Нажмите
Save resultдля сохранения.
Cuneiform-Qt сохраняет результат в HTML-файл. Это удобно, когда нужно быстро получить текст из изображения без командной строки и без сложной настройки. При этом сама оболочка не является отдельным OCR-движком: распознавание выполняет CuneiForm.
Распознавание через командную строку
Командная строка — сильная сторона CuneiForm. Она позволяет запускать распознавание без графического интерфейса, повторять одинаковые операции и включать OCR в автоматизированную обработку сканов.
Базовый шаблон команды:
cuneiform [параметры] inputРаспознавание русского текста в обычный TXT:
cuneiform -l rus -f text -o result.txt scan.bmpРаспознавание смешанного русского и английского текста в RTF:
cuneiform -l ruseng -f rtf -o result.rtf scan.bmpРаспознавание английской одноколоночной страницы в HTML:
cuneiform --singlecolumn -l eng -f html -o result.html scan.bmpРаспознавание факсового документа:
cuneiform --fax -l rus -f text -o fax-result.txt fax-page.bmpРаспознавание матричной распечатки:
cuneiform --dotmatrix -l rus -f text -o matrix-result.txt old-print.bmpЕсли файл результата не задан параметром -o, CuneiForm создаёт файл cuneiform-out.format, где расширение зависит от выбранного формата вывода.
Работа через OCRFeeder
OCRFeeder — графическая OCR-среда для GNOME, которая автоматически выделяет содержимое изображения, отличает графику от текста и выполняет OCR для текстовых областей. Она поддерживает импорт PDF, очистку входных изображений, исправление нераспознанных символов, работу с ограничивающими рамками, стили абзацев, сохранение и загрузку проекта, а также экспорт в несколько форматов; основным форматом результата назван ODT.
CuneiForm в таком сценарии используется как один из OCR-движков. Это удобно, когда пользователь хочет графическую среду с разметкой документа, но при этом предпочитает использовать именно OCR-движок CuneiForm. По сравнению с Cuneiform-Qt, OCRFeeder шире по возможностям подготовки документа; по сравнению с чистой командной строкой, он проще для ручной разметки и проверки.
Поддерживаемые входные изображения и ограничения форматов
В Linux-версии CuneiForm входной файл описан как одиночное изображение, которое умеет открыть GraphicsMagick. Это важная формулировка: список входных форматов зависит не только от CuneiForm, но и от возможностей графической библиотеки, через которую файл читается.
Практически это означает следующее:
| Ситуация | Что учитывать |
|---|---|
| Одиночный скан страницы | подходит для командного запуска |
| Многостраничный документ | требует предварительного разделения на страницы или внешней оболочки |
| удобнее обрабатывать через OCRFeeder или предварительно преобразовывать страницы в изображения | |
| BMP | надёжный базовый вариант для старых сборок |
| TIFF, PNG, JPEG | применимость зависит от сборки и библиотек обработки изображений |
| Фотография страницы | нужна предварительная подготовка: выравнивание, обрезка, контраст |
OCR CuneiForm лучше рассматривать как двигатель распознавания страницы, а не как современный универсальный документ-менеджер. Для PDF-документов, массовой конвертации, объединения и разделения файлов пригодятся отдельные инструменты: PDFsam для операций со страницами, WinScan2PDF для простого создания PDF со сканера, PaperScan Free для сканирования и обработки изображений, PDF Shaper Free для набора PDF-операций.
Системные требования
Windows-сценарий
Windows-версия Cognitive OpenOCR/CuneiForm работает как настольная OCR-программа с графическим интерфейсом. На старых страницах каталогов ПО она описывается как Windows-приложение, а в интерфейсе видны классические элементы Windows: меню, панели инструментов, мастер распознавания, выбор TWAIN-драйвера сканера и окно General settings. Для Cognitive OpenOCR указывались платформа Windows, язык интерфейса English и доступные языки English и Russian.
Для Windows-сценария важны не столько объём памяти и частота процессора, сколько совместимость со сканером и качество исходного изображения. Если используется сканер, программа работает через драйвер; если используется готовый файл, важен формат изображения и читаемость текста.
Linux-порт
Cuneiform for Linux проверялся на Linux, FreeBSD, OS X и Windows-сборках через MSVC, MinGW и Cygwin. В этой ветке есть два зафиксированных ограничения: работа только на x86 и amd64, а также отсутствие распознавания таблиц.
Для сборки на Unix используется CMake. Стандартная последовательность сборки: создать каталог сборки, перейти в него, выполнить cmake, затем make и make install. Это технический сценарий для пользователей, которые собирают программу из исходного кода, а не запускают готовую графическую сборку.
Cuneiform-Qt
Cuneiform-Qt требует Qt4 или Qt5 и установленный CuneiForm. Это не самостоятельная OCR-система, а интерфейсная оболочка. Она нужна, когда пользователь хочет работать через окно с кнопками Open image, Recognize text, Save result, но распознавание должен выполнять движок CuneiForm.
Требования к исходникам
Для качественного результата OCR CuneiForm нужны:
чёткое изображение страницы;
достаточный контраст между текстом и фоном;
правильная ориентация;
отсутствие сильного перекоса;
печатный, а не рукописный текст;
правильно выбранный язык;
один файл страницы для командной обработки;
специальный режим для факса или матричной печати, когда исходник относится к этим типам.
Чем хуже исходник, тем больше ручной вычитки требуется после распознавания. OCR CuneiForm не заменяет проверку результата, особенно в документах с цифрами, фамилиями, техническими обозначениями, артикулами и адресами.
Преимущества и ограничения OCR CuneiForm
Плюсы
Открытая история и BSD-лицензирование ядра. Код Cuneiform был открыт в 2008 году, для распространения выбрана BSD-лицензия. Это сделало программу важной для открытой OCR-экосистемы и портов.
Поддержка русского текста. CuneiForm поддерживает русский язык через
rus, а для смешанного русско-английского текста естьruseng.Командная строка. Распознавание можно запускать через
cuneiformс параметрами языка, формата и файла результата.Несколько форматов вывода. Поддерживаются
text,smarttext,rtf,html,hocr,native.Специальные режимы для факса и матричной печати. Параметры
--faxи--dotmatrixориентированы на сложные старые исходники.Графические оболочки. Cuneiform-Qt даёт простой интерфейс, а OCRFeeder позволяет использовать CuneiForm внутри более развитой графической OCR-среды.
Локальная обработка. Командный сценарий не требует отправлять документ в облачный сервис.
Минусы
Нет распознавания таблиц в Linux-порте. Для документов с таблицами, ведомостями и сложными бланками это серьёзное ограничение.
Ограничение архитектур Linux-порта. В Linux-порте названы x86 и amd64.
Результат требует вычитки. Особенно это заметно на слабоконтрастных изображениях, факсах, фотографиях и старых сканах.
Графический интерфейс зависит от выбранной оболочки. Командная версия удобна техническим пользователям, но новичку проще работать через Cuneiform-Qt или OCRFeeder.
Не подходит для рукописного текста. Программа рассчитана на печатные материалы; рукописные и декоративные шрифты находятся за пределами её нормального сценария.
Современные OCR-пайплайны чаще строят на Tesseract. Tesseract активнее используется в новых интеграциях, поддерживает больше современных форматов вывода и имеет развитую экосистему сторонних оболочек.
Сравнение с аналогами
OCR CuneiForm и Tesseract OCR
Tesseract OCR — главный открытый конкурент CuneiForm в современных OCR-сценариях. Он поддерживает plain text, hOCR, PDF, invisible-text-only PDF, TSV, ALTO и PAGE. При этом основной проект Tesseract не включает собственное GUI-приложение; для интерфейса используются сторонние оболочки.
| Критерий | OCR CuneiForm | Tesseract OCR |
|---|---|---|
| Тип | OCR-движок и историческая Windows-программа | OCR-движок и командная программа |
| Русский текст | поддерживается | поддерживается при наличии языковых данных |
| Смешанный русский/английский | есть код ruseng | настраивается через языковые модели |
| Форматы результата | text, rtf, html, hocr, smarttext, native | plain text, hOCR, PDF, invisible-text-only PDF, TSV, ALTO, PAGE |
| GUI | Windows-интерфейс, Cuneiform-Qt, OCRFeeder | сторонние оболочки |
| Сильная сторона | простая командная OCR-обработка, историческая поддержка русского текста | современная экосистема, форматы, интеграции |
| Ограничение | Linux-порт без распознавания таблиц | без встроенной GUI-программы |
CuneiForm удобен для тех, кто работает с его понятной командной схемой и русско-английскими документами. Tesseract лучше подходит для новых проектов, где важны PDF с невидимым текстовым слоем, TSV/ALTO/PAGE и активная экосистема.
OCR CuneiForm и ABBYY FineReader PDF
ABBYY FineReader PDF — коммерческий PDF- и OCR-пакет. Он предназначен не только для распознавания, но и для редактирования PDF, конвертации, сравнения документов, защиты, комментирования и совместной работы с документами. В пробном режиме FineReader PDF Corporate предоставляет 7 дней полной функциональности для работы с PDF, а сохранение результатов после OCR ограничено 100 страницами.
| Критерий | OCR CuneiForm | ABBYY FineReader PDF |
|---|---|---|
| Модель | открытая OCR-система и бесплатные сценарии | коммерческий PDF/OCR-пакет |
| Основная задача | распознавание текста со скана | полный документооборот с PDF и OCR |
| Интерфейс | классический Windows-интерфейс или внешние оболочки | современный PDF-редактор |
| Командная автоматизация | сильная сторона Linux-порта | есть корпоративные функции автоматизации |
| Работа с PDF | требует внешних инструментов или оболочек | встроенная работа с PDF |
| Кому подходит | техническим пользователям, архивным задачам, простому OCR | офисам, юристам, бухгалтерам, документообороту |
| Ограничение | нет современного PDF-редактора | платная модель |
CuneiForm не заменяет FineReader PDF в задачах, где нужно редактировать PDF, сравнивать версии документов, готовить корпоративные файлы и работать с многостраничными потоками. Зато OCR CuneiForm остаётся применимым там, где нужен локальный открытый OCR-движок без тяжёлого PDF-комбайна.
OCR CuneiForm и OCRFeeder
OCRFeeder не является прямым конкурентом CuneiForm как движка: он выступает графической OCR-средой. OCRFeeder анализирует изображение, автоматически выделяет области, различает графику и текст, выполняет OCR для текстовых областей и экспортирует результат в несколько форматов, главным из которых назван ODT.
| Критерий | OCR CuneiForm | OCRFeeder |
|---|---|---|
| Тип | OCR-движок | графическая OCR-среда |
| Интерфейс | командная строка или отдельные оболочки | GTK-интерфейс |
| Роль в процессе | распознаёт текст | управляет разметкой, подготовкой, экспортом |
| Подход к результату | выбранный формат через -f | документный результат с разметкой |
| Связка | CuneiForm может быть движком | OCRFeeder может использовать CuneiForm |
| Сценарий | автоматизация или простое распознавание | визуальная подготовка и исправление OCR |
OCRFeeder стоит выбирать, когда пользователю нужен графический контроль документа: области, рамки, стили, исправление символов, проект и экспорт. CuneiForm нужен как распознающий модуль внутри такой схемы.
OCR CuneiForm и GOCR
GOCR — свободный OCR-движок. В старых Linux-сценариях его часто рассматривали рядом с CuneiForm, Ocrad и Tesseract. GOCR проще по модели применения, но CuneiForm сильнее выглядит в контексте многоязычности, русско-английского режима и исторически развитого Windows-интерфейса.
| Критерий | OCR CuneiForm | GOCR |
|---|---|---|
| Тип | многоязычная OCR-система | свободный OCR-движок |
| Русский сценарий | есть rus и ruseng | зависит от возможностей конкретной сборки и задачи |
| Интерфейс | Windows GUI, Cuneiform-Qt, OCRFeeder | обычно через командную строку или сторонние оболочки |
| Специальные режимы | факс, матричная печать, одна колонка | базовый OCR-сценарий |
| Сценарий | документы, сканы, архивы | простое извлечение текста из изображений |
GOCR уместен для экспериментов и простых OCR-задач, но для русскоязычных сканов CuneiForm выглядит более предметно, особенно при использовании параметров языка и режима документа.
OCR CuneiForm и Cuneiform-Qt
Cuneiform-Qt — не аналог движка, а оболочка для него. Сравнивать их нужно как ядро и интерфейс.
| Критерий | CuneiForm | Cuneiform-Qt |
|---|---|---|
| Роль | распознаёт текст | даёт окно для работы с CuneiForm |
| Запуск | командная строка или интеграция | графическая кнопочная схема |
| Основные действия | язык, формат, режим, файл результата | Open image, Recognize text, Save result |
| Результат | зависит от параметра -f | HTML |
| Кому подходит | техническим пользователям | новичкам в Linux, которым нужен простой интерфейс |
Cuneiform-Qt полезен как быстрый вход в OCR CuneiForm: открыть изображение, распознать, сохранить результат. Когда нужны разные форматы вывода, пакетная обработка и точные параметры, удобнее командная строка.
Отзывы пользователей и профильных журналов
Мнение профильных изданий
CNews рассматривал CuneiForm прежде всего как значимый переход OCR-технологии к бесплатному и открытому распространению. В публикации 2007 года подчёркивалась бесплатность OCR CuneiForm и её ориентация на распознавание печатных текстов, а в ленте Cognitive CuneiForm отражены ключевые события 2007–2010 годов: бесплатная версия, открытие кода, Linux-версия ядра, открытие исходных текстов интерфейса и новые версии Linux-ветки.
ITC в обзоре OCR CuneiForm V.12 выделял бесплатность и поддержку большого количества языков, но отмечал проблемы с запуском и нестабильное качество распознавания. Там же описаны сильные стороны для смешанного русского и английского текста, автоматического поиска элементов страницы, работы с матричными распечатками и факсами.
Архив Мир ПК показывает CuneiForm как важный продукт Cognitive Technologies на этапе перехода к открытому коду. В заметке говорится, что CuneiForm снова становится флагманским продуктом компании, а технология распознавания использовалась в комплектах многих сканеров известных производителей.
Усреднённое мнение пользователей сети
В пользовательских обсуждениях OCR CuneiForm чаще оценивают как бесплатную программу, способную дать приемлемый результат при хорошем скане и ручной настройке, но уступающую FineReader по удобству. На странице DWG.ru CuneiForm описана как бесплатная программа для перевода сканов в текст; там же зафиксирована типичная оценка: программа слабее FineReader по удобству, но при правильной ручной настройке и нормальном качестве сканов даёт приемлемые результаты.
Такая оценка хорошо совпадает с реальными ограничениями CuneiForm. Программа не является решением, где пользователь нажимает одну кнопку и всегда получает готовый безошибочный документ. Она требует корректного языка, чистого изображения, правильного режима и последующей проверки. При этом для бесплатной OCR-системы с русским языком, командной строкой и открытой историей она остаётся заметным инструментом.
Типичные ошибки при работе с OCR CuneiForm
Неправильный язык распознавания
Ошибка с языком сразу ухудшает результат. Русский документ нужно распознавать с -l rus, смешанный русский и английский — с -l ruseng, английский — с -l eng. В графическом интерфейсе язык выбирается в Recognition language.
Пример неправильного сценария: пользователь распознаёт русско-английскую инструкцию как чистый русский текст. В результате латинские обозначения моделей, единицы измерения и английские сокращения превращаются в похожие кириллические наборы. Для технических документов это критично.
Попытка распознать рукописный текст
OCR CuneiForm предназначена для печатного текста. Рукописные заметки, подписи, конспекты, заполненные от руки поля и декоративные надписи не относятся к её нормальной области применения. Для таких материалов нужен другой класс распознавания.
Слабое качество скана
Плохой скан порождает ошибки ещё до выбора формата результата. Частые проблемы:
низкое разрешение;
размытые буквы;
серый фон;
тени;
перекос страницы;
следы сгиба;
сжатие JPEG;
обрезанные края строк;
просвечивание оборота страницы.
В таких случаях полезнее сначала улучшить изображение, чем повторно запускать OCR с теми же настройками. Нужны поворот, обрезка, выравнивание, повышение контраста, перевод в чёрно-белый режим или пересканирование.
Ожидание точного восстановления таблиц в Linux-порте
В Linux-порте CuneiForm нет распознавания таблиц. Это означает, что табличные документы не нужно воспринимать как гарантированно сохраняемые структуры. Если цель — получить редактируемую таблицу из скана, лучше выбрать другой инструмент или готовиться к ручной переработке результата.
Неправильный формат результата
text хорош для чистого текста, но теряет оформление. rtf лучше подходит для редактируемого документа. html удобен для просмотра и публикации. hocr нужен для OCR-разметки и машинной обработки. Ошибка выбора формата не ухудшает само распознавание, но создаёт лишнюю работу после него.
Запуск без проверки результата
OCR-результат всегда нужно читать. Даже при хорошем изображении программа может ошибиться в похожих символах: 0 и О, 1 и I, rn и m, с и c, а и a. В документах с номерами, адресами, артикулами, датами и суммами ручная проверка обязательна.
Практические сценарии применения OCR CuneiForm
Разовая обработка скана
Для одной страницы удобнее использовать графический интерфейс. Windows-версия позволяет открыть изображение через мастер, выбрать язык и запустить распознавание. Cuneiform-Qt ещё проще: Open image, затем Recognize text, затем Save result.
Такой сценарий подходит для:
одной страницы книги;
письма;
инструкции;
машинописной справки;
старого документа;
скана с русским текстом.
Главное — сразу выбрать язык. Для русского текста нужен rus, для русско-английского документа — ruseng.
Распознавание пачки однотипных изображений
Для регулярной обработки лучше командная строка. Пример логики:
сканер или внешний инструмент сохраняет страницы в отдельные изображения;
скрипт перебирает файлы;
для каждого файла запускается
cuneiform;результат сохраняется в TXT, RTF, HTML или hOCR;
итоговые файлы отправляются в архив, редактор или систему поиска.
Командная строка особенно полезна, когда документы однотипные: один язык, одинаковое качество сканов, один формат результата. В таком случае пользователь один раз подбирает параметры, а затем повторяет их для всех страниц.
Распознавание русско-английских документов
CuneiForm удобен для документов, где кириллица и латиница смешиваются в одном тексте. Это могут быть:
инструкции к устройствам;
счета с латинскими артикулами;
технические паспорта;
документы с названиями программ;
учебные материалы;
старые распечатки с командами и русскими пояснениями.
Для таких документов используйте ruseng. Этот режим лучше соответствует смешанному тексту, чем чистый rus или eng.
Обработка факсов
Факс снижает качество текста: появляются полосы, шум, неровные контуры и потеря мелких деталей. Для таких исходников используйте --fax.
Пример:
cuneiform --fax -l rus -f text -o result.txt fax.bmpПосле распознавания факса особенно важна вычитка. Факсовые искажения часто затрагивают цифры, знаки препинания, короткие слова и фамилии.
Матричная печать
Документы с матричных принтеров имеют точечную структуру букв. Обычный OCR не всегда правильно воспринимает такие символы, поэтому в CuneiForm есть режим --dotmatrix.
Пример:
cuneiform --dotmatrix -l rus -f rtf -o old-report.rtf old-report.bmpЭтот режим полезен для старых ведомостей, накладных, отчётов и распечаток с перфорированной бумаги. После распознавания таких материалов нужно сверять числа и сокращения.
Работа с результатом после распознавания
TXT
TXT подходит для чистого текста. Его удобно использовать для:
поиска;
копирования фрагментов;
загрузки в редактор;
последующей обработки скриптами;
хранения распознанных архивных текстов.
Минус TXT — отсутствие оформления. Если в документе важны заголовки, таблицы, отступы и визуальная структура, простой текст потребует ручного восстановления.
RTF
RTF удобен для редактирования. Такой формат открывается в текстовых редакторах и сохраняет больше структуры, чем TXT. Его лучше выбирать, когда результат нужно вычитать, исправить и оформить.
Пример:
cuneiform -l rus -f rtf -o document.rtf page.bmpRTF подходит для писем, статей, инструкций и материалов, которые затем будут дорабатываться вручную.
HTML
HTML полезен, когда результат нужно просмотреть в браузере или встроить в веб-процесс. Cuneiform-Qt сохраняет результат в HTML, поэтому этот формат часто встречается в графическом сценарии Linux.
Пример:
cuneiform -l ruseng -f html -o page.html page.bmpHTML удобен для быстрой проверки структуры, но для обычного редактирования текста чаще проще RTF или TXT.
hOCR
hOCR — формат для OCR-разметки. Он нужен не обычному пользователю, а тем, кто строит цепочку обработки: хранит координаты, связывает текст с изображением, индексирует страницы, делает поисковый слой или обрабатывает OCR-результат программно.
Пример:
cuneiform -l eng -f hocr -o page.html page.bmpДля архивов и библиотечных проектов hOCR полезнее простого TXT, потому что сохраняет связь текста с положением на странице.
Как выбрать режим и формат
| Задача | Язык | Режим | Формат |
|---|---|---|---|
| Русский скан книги | rus | обычный или --singlecolumn | rtf или text |
| Инструкция с русским и английским | ruseng | обычный | rtf |
| Английская статья | eng | --singlecolumn, если одна колонка | text или html |
| Факсовый документ | rus или eng | --fax | text |
| Матричная распечатка | нужный язык | --dotmatrix | text или rtf |
| OCR-разметка для обработки | нужный язык | по структуре страницы | hocr |
| Быстрая графическая работа в Linux | зависит от текста | через Cuneiform-Qt | HTML |
Для большинства бытовых задач достаточно трёх решений: rus или ruseng для языка, rtf для редактирования, --singlecolumn для простой страницы. Остальные параметры нужны для специальных документов.
Для кого подходит OCR CuneiForm
Новичку
Новичку лучше начинать с Cuneiform-Qt или Windows-интерфейса. В Cuneiform-Qt процесс сводится к трём действиям: открыть изображение, распознать, сохранить. Такой сценарий понятнее, чем командная строка, и позволяет увидеть исходник рядом с результатом.
OCR CuneiForm подойдёт новичку, если задача простая: один скан, печатный текст, русский или английский язык, несложная структура страницы. Для PDF-документов, таблиц и большого архива лучше выбрать более современный инструмент или использовать CuneiForm только как часть цепочки.
Опытному пользователю
Опытному пользователю CuneiForm интересен командной строкой. Можно настроить язык, формат, режим документа и имя результата. Командный запуск удобен для повторяемых операций и архивной обработки.
Пример сценария:
for file in scans/*.bmp; do base=$(basename "$file" .bmp) cuneiform -l rus -f text -o "texts/$base.txt" "$file"doneТакой подход подходит для набора однотипных страниц. После распознавания файлы можно объединить, проиндексировать, отправить в редактор или загрузить в систему хранения.
Архивисту и исследователю
OCR CuneiForm полезна при работе со старыми печатными материалами: машинописными страницами, инструкциями, старой технической документацией, распечатками и сканами. Сильная сторона программы — сочетание русского языка, локальной обработки и специальных режимов для факса и матричной печати.
Ограничение — ручная проверка. В архивных документах часто встречаются пятна, заломы, неровная бумага, нестандартные шрифты и повреждения. OCR ускоряет перенос текста, но не отменяет сверку с оригиналом.
Офисному пользователю
Для простого извлечения текста из одного скана CuneiForm подходит. Для регулярного офисного документооборота с PDF, комментариями, защитой, конвертацией в Word/Excel и сравнением документов лучше смотреть в сторону специализированных PDF/OCR-пакетов. ABBYY FineReader PDF закрывает больше офисных задач, но относится к другому классу ПО.
Разработчику и системному администратору
Разработчику CuneiForm интересна как командная утилита. Её можно включить в скрипт, обработчик входящих сканов или локальный OCR-процесс. В этом сценарии важны стабильные входные форматы, заранее выбранный язык и понятное именование выходных файлов.
Для новых проектов стоит сравнить CuneiForm с Tesseract. Tesseract поддерживает больше современных форматов вывода и не содержит встроенного GUI-приложения, но его экосистема активнее и шире.
Когда лучше выбрать альтернативу
OCR CuneiForm не универсальна. Есть задачи, где другой инструмент подходит лучше.
| Задача | Более подходящий вариант |
|---|---|
| Поисковый PDF с невидимым текстовым слоем | Tesseract OCR или PDF/OCR-пакет |
| Редактирование PDF после распознавания | ABBYY FineReader PDF |
| Сложные таблицы | ABBYY FineReader PDF или другой инструмент с табличным OCR |
| Графическая разметка документа в Linux | OCRFeeder |
| Простое окно для CuneiForm | Cuneiform-Qt |
| Массовая современная OCR-интеграция | Tesseract OCR |
| Рукописный текст | специализированные решения для handwriting recognition |
| Сканирование в PDF без OCR | WinScan2PDF |
| Чтение PDF без распознавания | Adobe Acrobat Reader, Foxit Reader, Sumatra PDF |
CuneiForm стоит выбирать не по принципу самая новая OCR-программа, а по задаче: печатный текст, локальная обработка, русский или русско-английский документ, командный запуск, простая автоматизация.
FAQ
Чем OCR CuneiForm отличается от Cognitive OpenOCR?
Это связанные названия одной OCR-системы. OCR CuneiForm — историческое название программы Cognitive Technologies. Cognitive OpenOCR и CuneiForm OpenOCR встречаются как названия открытой или распространяемой версии. В контексте распознавания текста речь идёт о системе CuneiForm и её вариантах.
Есть ли у CuneiForm графический интерфейс?
Да. У Windows-версии есть классический графический интерфейс с меню, панелью инструментов, мастером распознавания и настройками. Для Linux есть Cuneiform-Qt — графический фронтенд с кнопками Open image, Recognize text, Save result. Также CuneiForm можно использовать через OCRFeeder.
Можно ли распознавать русский текст?
Да. В командной версии русский язык выбирается параметром -l rus. Для смешанного русского и английского текста используется -l ruseng.
Какие форматы вывода поддерживаются?
Поддерживаются html, hocr, native, rtf, smarttext, text. Формат выбирается параметром -f. По умолчанию используется plain text.
Подходит ли OCR CuneiForm для рукописного текста?
Нет. Программа рассчитана на печатные материалы. Рукописный текст, декоративные шрифты и нестандартные надписи не относятся к её нормальному сценарию.
Можно ли распознавать таблицы?
В Linux-порте CuneiForm распознавания таблиц нет. Для документов, где таблицы являются главным содержанием, лучше выбирать другой инструмент или готовиться к ручному восстановлению структуры.
Чем CuneiForm отличается от Tesseract?
Обе программы относятся к OCR-движкам, но Tesseract активнее применяется в современных проектах и поддерживает больше форматов вывода: plain text, hOCR, PDF, invisible-text-only PDF, TSV, ALTO и PAGE. CuneiForm интересен исторической поддержкой русского текста, режимом ruseng, специальными режимами для факса и матричной печати, а также классическим Windows-интерфейсом и простыми оболочками.
Когда использовать Cuneiform-Qt?
Cuneiform-Qt подходит, когда нужен простой графический сценарий: открыть изображение, распознать текст и сохранить результат. Он особенно удобен для пользователей Linux, которым не нужна командная строка.
Когда использовать OCRFeeder вместе с CuneiForm?
OCRFeeder подходит, когда нужно не просто распознать текст, а работать с областями страницы, исправлять нераспознанные символы, задавать рамки, очищать входное изображение, импортировать PDF и экспортировать документ в несколько форматов. CuneiForm в таком сценарии используется как OCR-движок.
Итоговые рекомендации
OCR CuneiForm OpenOCR стоит использовать для локального распознавания печатных сканов, особенно когда нужен русский или смешанный русско-английский текст, командная строка, RTF/TXT/HTML/hOCR и специальные режимы для факсов или матричных распечаток. Это не современный PDF-комбайн и не инструмент для рукописного текста, а конкретная OCR-система с сильной историей, открытой веткой и понятной ролью в обработке печатных документов.
Для одной страницы удобнее графический интерфейс или Cuneiform-Qt. Для повторяемых задач лучше командная строка. Для визуальной разметки и подготовки документов в Linux подходит OCRFeeder с CuneiForm в качестве движка. Для современных OCR-пайплайнов, PDF с невидимым текстовым слоем и расширенных форматов вывода стоит сравнить CuneiForm с Tesseract. Для офисной работы с PDF, редактированием, сравнением документов и сложным документооборотом практичнее коммерческие PDF/OCR-пакеты вроде ABBYY FineReader PDF.

Оставте свой отзыв о OCR CuneiForm